接口需求:
- 设置定时任务,每隔
10分钟爬取新浪微博、知乎、百度实时热搜数据。 - 爬取到数据后不直接返回给前端,先写入一个
.json格式的文件。 - 服务端渲染的后台接口请求并返回给前端
json文件的内容。
创建工程
初始化
- 首先得找到目标站点,如下:
- 微博热搜地址:https://s.weibo.com/top/summary?cate=realtimehot
- 百度热搜地址:https://top.baidu.com/buzz?b=2&c=12&fr=topcategory_c12
- 知乎热搜地址:https://tophub.today/n/mproPpoq6O
- 创建文件夹
weibo - 进入文件夹根目录
- 使用
npm init -y快速初始化一个项目
安装依赖
- 创建
app.js文件 - 安装依赖:
npm i cheerio superagent -D
cheerio 是 nodejs 的抓取页面模块,为服务器特别定制的,快速、灵活、实施的 jQuery 核心实现。适合各种 Web 爬虫程序。node.js 版的 jQuery。
superagent 是一个轻量级、渐进式的请求库,内部依赖 nodejs 原生的请求 api,适用于 nodejs 环境。
代码编写
- 打开
app.js,开始完成主要功能 - 首先在顶部引入
cheerio、superagent以及 nodejs 中的fs模块
const cheerio = require("cheerio");
const superagent = require("superagent");
const fs = require("fs");- 通过变量的方式声明热搜的url,便于后面 复用
superagent
使用 superagent 发送get请求superagent 的 get 方法接收两个参数。第一个是请求的 url 地址,第二个是请求成功后的回调函数。
回调函数有俩参数,第一个参数为 error ,如果请求成功,则返回 null,反之则抛出错误。第二个参数是请求成功后的 响应体
superagent.get(hotSearchURL, (err, res) => {
if (err) console.error(err);
});网页元素分析
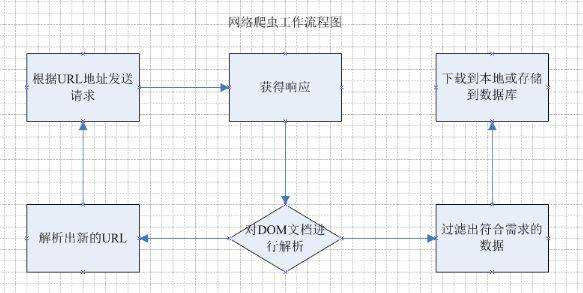
打开目标站对网页中的 DOM 元素进行一波分析。对 jQuery 比较熟的小老弟,看到下图如此简洁清晰明了的 DOM 结构,是不是有 N 种取出它每个 tr 中的数据并 push 到一个 Array 里的方法呢?

微博热搜页面结构

百度热搜页面结构

知乎热搜页面结构
对!我们最终的目的就是要通过 jQuery 的语法,遍历每个 tr ,并将其每一项的 热搜地址 、热搜内容 、 热度值 、序号 、表情等信息 push 进一个空数组中。
再将它通过 nodejs 的 fs 模块,写入一个 json 文件中。
jQuery 遍历拿出数据
使用 jQuery 的 each 方法,对 tbody 中的每一项 tr 进行遍历,回调参数中第一个参数为遍历的下标 index,第二个参数为当前遍历的元素,一般 $(this) 指向的就是当前遍历的元素。
let hotList = [];
// 微博热搜
$("#pl_top_realtimehot table tbody tr").each(function (index) {
if (index !== 0) {
const $td = $(this).children().eq(1);
const link = weiboURL + $td.find("a").attr("href");
const text = $td.find("a").text();
const hotValue = $td.find("span").text();
const icon = $td.find("img").attr("src")
? "https:" + $td.find("img").attr("src")
: "";
hotList.push({
index,
link,
text,
hotValue,
icon,
});
}
});
// 百度热搜
$("#main .mainBody .grayborder table tbody tr").each(function (index) {
if (index !== 0 && index <= count) {
const $td = $(this).children().eq(1);
const link = $td.find("a").attr("href");
// const detail = $td.find("a").attr("href_top");
const text = $td.find(".list-title").text();
const $hotValTd = $(this).children().eq(3);
const hotValue = $hotValTd.find("span").text(); const icon = false ? "https://top.bdimg.com/frontend/static/common/" + $hotValTd.find(".last span")[0].style.background : "";
hotList.push({
index,
link,
text,
hotValue,
icon,
});
}
});
// 知乎热搜
$("#page .c-d .Zd-p-Sc .cc-dc .cc-dc-c .jc .jc-c table tbody tr").each(function (index) {
if (index >= 0 && index < count) {
const $td = $(this).children().eq(1);
const link = weiboURL + $td.find("a").attr("href");
const text = $td.find("a").text();
const hotValue = $(this).children().eq(2).text();
const icon = false ? "https:" + $td.find("img").attr("src") : "";
hotList.push({
index: index + 1,
link,
text,
hotValue,
icon,
});
}
});
cheerio 包装请求后的响应体
在 nodejs 中,要想向上面那样愉快的写 jQuery 语法,还得将请求成功后返回的响应体,用 cheerio 的 load 方法进行包装。
const $ = cheerio.load(res.text);写入 json 文件
接着使用 nodejs 的 fs 模块,将创建好的数组转成 json字符串,最后写入当前文件目录下的 hotSearch.json 文件中(无此文件则会自动创建)。
fs.writeFileSync(
`${__dirname}/hotSearch.json`,
JSON.stringify(hotList),
"utf-8"
);完整代码如下:
const cheerio = require("cheerio");
const superagent = require("superagent");
const fs = require("fs");
const weiboURL = "https://s.weibo.com";
const hotSearchURL = weiboURL + "/top/summary?cate=realtimehot";
superagent.get(hotSearchURL, (err, res) => {
if (err) console.error(err);
const $ = cheerio.load(res.text);
let hotList = [];
$("#pl_top_realtimehot table tbody tr").each(function (index) {
if (index !== 0) {
const $td = $(this).children().eq(1);
const link = weiboURL + $td.find("a").attr("href");
const text = $td.find("a").text();
const hotValue = $td.find("span").text();
const icon = $td.find("img").attr("src")
? "https:" + $td.find("img").attr("src")
: "";
hotList.push({
index,
link,
text,
hotValue,
icon,
});
}
});
fs.writeFileSync(
`${__dirname}/hotSearch.json`,
JSON.stringify(hotList),
"utf-8"
);
});
// 百度热搜和知乎热搜 写法一样,就不重复写了,后面会封装好完整代码,往下看打开终端,输入 node app,可看到根目录下多了个 hotSearch.json 文件。
定时爬取
虽然代码可以运行,也能爬取到数据并存入 json 文件。
但是,每次都要手动运行,才能爬取到当前时间段的热搜数据,这一点都 不人性化!
最近微博热搜瓜这么多,咱可是一秒钟可都不能耽搁。我们最开始期望的是每隔多长时间 定时执行爬取 操作。瓜可不能停!
接下来,对代码进行 小部分改造。
数据请求封装
由于 superagent 请求是个异步方法,我们可以将整个请求方法用 Promise 封装起来,然后 每隔指定时间 调用此方法即可。
function getHotSearchList() {
return new Promise((resolve, reject) => {
superagent.get(hotSearchURL, (err, res) => {
if (err) reject("request error");
const $ = cheerio.load(res.text);
let hotList = [];
$("#pl_top_realtimehot table tbody tr").each(function (index) {
if (index !== 0) {
const $td = $(this).children().eq(1);
const link = weiboURL + $td.find("a").attr("href");
const text = $td.find("a").text();
const hotValue = $td.find("span").text();
const icon = $td.find("img").attr("src")
? "https:" + $td.find("img").attr("src")
: "";
hotList.push({
index,
link,
text,
hotValue,
icon,
});
}
});
hotList.length ? resolve(hotList) : reject("errer");
});
});
}node-schedule 详解
定时任务我们可以使用 node-schedule 这个 nodejs库 来完成。
https://github.com/node-schedule/node-schedule
先安装
npm i node-schedule -D
头部引入
const nodeSchedule = require("node-schedule");
用法(每分钟的第 30 秒定时执行一次):
const rule = "30 * * * * *";
schedule.scheduleJob(rule, () => {
console.log(new Date());
});规则参数
* * * * * *
┬ ┬ ┬ ┬ ┬ ┬
│ │ │ │ │ │
│ │ │ │ │ └ day of week (0 - 7) (0 or 7 is Sun)
│ │ │ │ └───── month (1 - 12)
│ │ │ └────────── day of month (1 - 31)
│ │ └─────────────── hour (0 - 23)
│ └──────────────────── minute (0 - 59)
└───────────────────────── second (0 - 59, OPTIONAL)6 个占位符从左到右依次代表:秒、分、时、日、月、周几* 表示通配符,匹配任意。当 * 为秒时,表示任意秒都会触发,其他类推。来看一个 每小时的第20分钟20秒 定时执行的规则
2020 * * * *
更多规则自行搭配。
定时爬取,写入文件
使用定时任务来执行上面的请求数据,写入文件操作:
nodeSchedule.scheduleJob("30 * * * * *", async function () {
try {
const hotList = await getHotSearchList();
await fs.writeFileSync(
`${__dirname}/hotSearch.json`,
JSON.stringify(hotList),
"utf-8"
);
} catch (error) {
console.error(error);
}
});别忘了 捕获异常
下面贴上完整微博,百度,知乎热搜定时抓取代码代码(可直接 ctrl c/v):
const cheerio = require("cheerio");
const charset = require("superagent-charset");
const superagent = require("superagent");
const fs = require("fs");
const nodeSchedule = require("node-schedule"); // 定时任务插件
charset(superagent)
// 需要抓取的条数
let count = 20;
// 微博热搜地址
const weiboURL = "https://s.weibo.com";
const hotSearchURL = weiboURL + "/top/summary?cate=realtimehot";
// 获取微博热搜数据
function getWeiBoHotSearchList() {
return new Promise((resolve, reject) => {
superagent.get(hotSearchURL, (err, res) => {
if (err) reject("request error");
const $ = cheerio.load(res.text);
let hotList = [];
$("#pl_top_realtimehot table tbody tr").each(function (index) {
if (index !== 0 && index <= count) {
const $td = $(this).children().eq(1);
const link = weiboURL + $td.find("a").attr("href");
const text = $td.find("a").text();
const hotValue = $td.find("span").text();
const icon = $td.find("img").attr("src")
? "https:" + $td.find("img").attr("src")
: "";
hotList.push({
index,
link,
text,
hotValue,
icon,
});
}
});
hotList.length ? resolve(hotList) : reject("errer");
});
});
}
// 百度热搜地址
const baiduURL = 'https://top.baidu.com'
const baiduHotSearchURL = baiduURL + '/buzz?b=2&c=12&fr=topcategory_c12'
// 获取百度热搜数据
function getBaiduHotSearchList() {
return new Promise((resolve,reject) => {
// 解决百度热搜页面编码格式 gb2312 乱码写法
superagent.get(baiduHotSearchURL).charset("gb2312").buffer(true).end((err, res) => {
if (err) reject("request error")
const $ = cheerio.load(res.text);
let hotList = [];
$("#main .mainBody .grayborder table tbody tr").each(function (index) {
if (index !== 0 && index <= count) {
const $td = $(this).children().eq(1);
const link = $td.find("a").attr("href");
// const detail = $td.find("a").attr("href_top")
const text = $td.find(".list-title").text();
const $hotValTd = $(this).children().eq(3)
const hotValue = $hotValTd.find("span").text();
const icon = false
? "https://top.bdimg.com/frontend/static/common/" + $hotValTd.find(".last span")[0].style.background
: "";
hotList.push({
index,
link,
text,
hotValue,
icon,
});
}
});
hotList.length ? resolve(hotList) : reject("errer");
})
})
}
// 知乎热搜地址
const zhihuURL = 'https://tophub.today'
const zhihuHotSearchURL = zhihuURL + '/n/mproPpoq6O'
// 获取知乎热搜数据
function getZhiHuHotSearchList() {
return new Promise((resolve, reject) => {
superagent.get(zhihuHotSearchURL, (err, res) => {
if (err) reject("request error");
const $ = cheerio.load(res.text);
let hotList = [];
$("#page .c-d .Zd-p-Sc .cc-dc .cc-dc-c .jc .jc-c table tbody tr").each(function (index) {
if (index >= 0 && index < count) {
const $td = $(this).children().eq(1);
const link = weiboURL + $td.find("a").attr("href");
const text = $td.find("a").text();
const hotValue = $(this).children().eq(2).text();
const icon = false
? "https:" + $td.find("img").attr("src")
: "";
hotList.push({
index: index + 1,
link,
text,
hotValue,
icon,
});
}
});
hotList.length ? resolve(hotList) : reject("errer");
});
});
}
// 运行爬取程序
async function run() {
let hotList = {
"weibo_hot_list": [],
"baidu_hot_list": [],
"zhihu_hot_list": []
};
try {
const weiboHotList = await getWeiBoHotSearchList();
hotList.weibo_hot_list = weiboHotList;
const baiduHotList = await getBaiduHotSearchList();
hotList.baidu_hot_list = baiduHotList;
const zhihuHotList = await getZhiHuHotSearchList();
hotList.zhihu_hot_list = zhihuHotList;
fs.writeFileSync(
`${__dirname}/hotSearch.json`,
JSON.stringify(hotList),
"utf-8"
);
} catch (error) {
console.error(error);
}
}
/**
* 定时任务插件的用法
* (每分钟的第 30 秒定时执行一次):
*
* * * * * *
┬ ┬ ┬ ┬ ┬ ┬
│ │ │ │ │ │
│ │ │ │ │ └ day of week (0 - 7) (0 or 7 is Sun)
│ │ │ │ └───── month (1 - 12)
│ │ │ └────────── day of month (1 - 31)
│ │ └─────────────── hour (0 - 23)
│ └──────────────────── minute (0 - 59)
└───────────────────────── second (0 - 59, OPTIONAL)
6 个占位符从左到右依次代表:秒、分、时、日、月、周几* 表示通配符,匹配任意。当 * 为秒时,表示任意秒都会触发,其他类推。来看一个 每小时的第20分钟20秒 定时执行的规则:
20 20 * * * *
*/
// 使用定时任务来执行上面的请求数据,写入文件操作:
nodeSchedule.scheduleJob("30 * * * * *", async function () {
run()
});直接输入密码:nodejs 获取GitHub源码下载地址(复制地址到地址栏打开)
[gzh2v keyword=”node爬虫” key=”nodejs”]https://github.com/MarkSJun/HotSearch[/gzh2v]
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
您必须登录才能参与评论!
立即登录
cc