网络爬虫开发
第1章 课程介绍
- 什么是爬虫
- 爬虫的意义
- 课程内容
- 前置知识
什么是爬虫
可以把互联网比做成一张“大网”,爬虫就是在这张大网上不断爬取信息的程序
所以一句话总结:爬虫是请求网站并提取数据的自动化程序
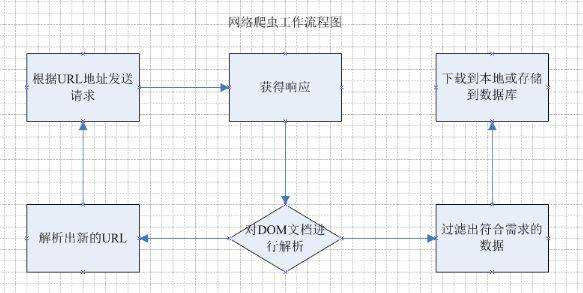
爬虫的基本工作流程如下:
- 向指定的URL发送http请求
- 获取响应(HTML、XML、JSON、二进制等数据)
- 处理数据(解析DOM、解析JSON等)
- 将处理好的数据进行存储
爬虫的意义
爬虫就是一个探测程序,它的基本功能就是模拟人的行为去各个网站转悠,点点按钮,找找数据,或者把看到的信息背回来。就像一只虫子在一幢楼里不知疲倦地爬来爬去。
你可以简单地想象:每个爬虫都是你的“分身”。就像孙悟空拔了一撮汗毛,吹出一堆猴子一样。
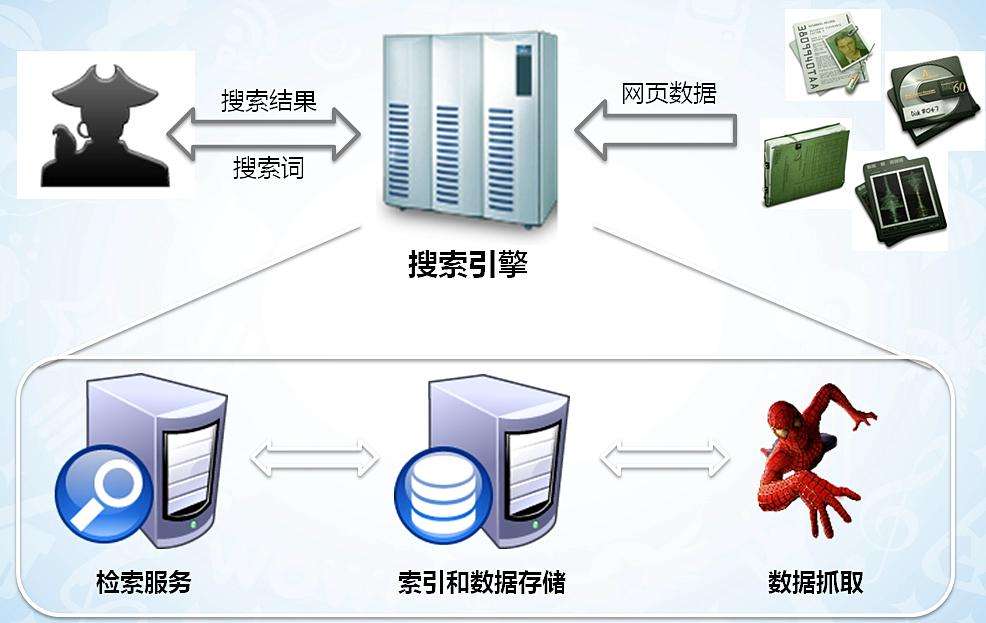
你每天使用的百度和Google,其实就是利用了这种爬虫技术:每天放出无数爬虫到各个网站,把他们的信息抓回来,存到数据库中等你来检索。
 抢票软件,就相当于撒出去无数个分身,每一个分身都帮助你不断刷新 12306 网站的火车余票。一旦发现有票,就马上下单,然后对你喊:大爷快来付款呀。
抢票软件,就相当于撒出去无数个分身,每一个分身都帮助你不断刷新 12306 网站的火车余票。一旦发现有票,就马上下单,然后对你喊:大爷快来付款呀。
在现实中几乎所有行业的网站都会被爬虫所 “骚扰”,而这些骚扰都是为了方便用户
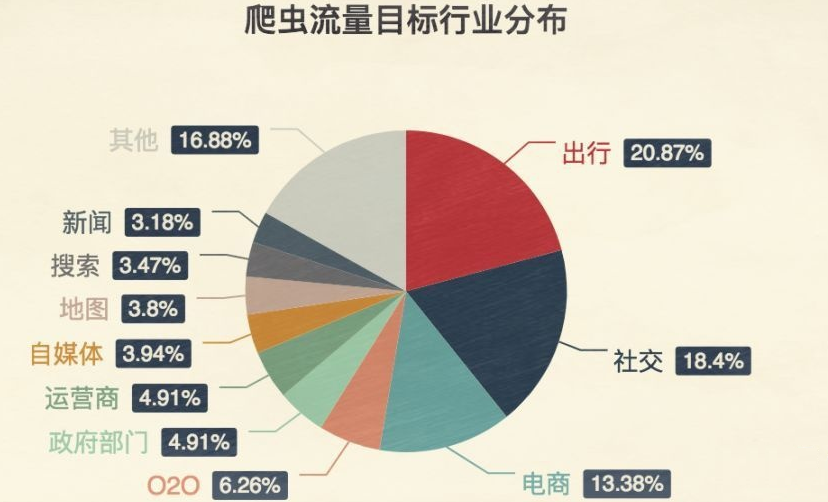
当然,有些网站是不能被过分骚扰的,其中排第一的就是出行类行业。
12306之所以会出如此变态的验证码,就是因为被爬虫折磨的无可奈何


正所谓道高一尺魔高一丈,某些爬虫工具,为了解决这种变态验证码,甚至推出了“打码平台”
原理就是爬虫还是不断工作,但只要遇到二维码,就通过打码平台下发任务,打码平台另一边就雇佣一大堆网络闲人,只要看到有验证码来了,就人工选一下验证码,完美的让程序与人工结合!
课程内容及目标
- 爬虫简介
- 制作一个自动下载图片的小爬虫
- 使用Selenium爬取动态网站
前置知识
- js基础
- node基础
第2章 爬虫基础
学习目标:
- 以
http://web.itheima.com/teacher.html网站目标为例,最终目的是下载网站中所有老师的照片:
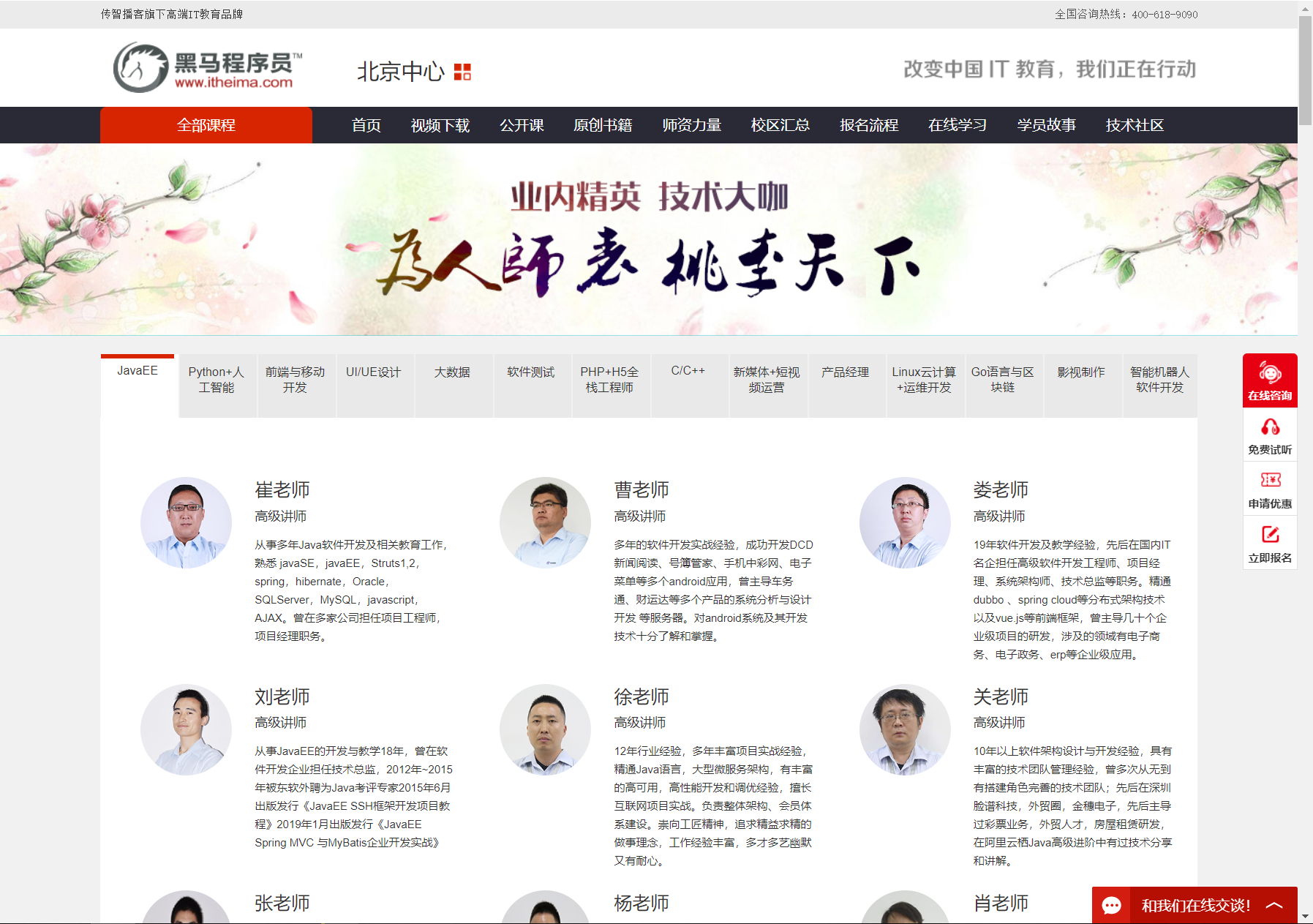
下载所有老师的照片,需要通过如下步骤实现:
- 发送http请求,获取整个网页内容
- 通过cheerio库对网页内容进行分析
- 提取img标签的src属性
- 使用download库进行批量图片下载
发送一个HTTP请求
学习目标:
- 发送HTTP请求并获取相应
在学习爬虫之前,需要对HTTP请求充分了解,因为爬虫的原理就是发送请求到指定URL,获取响应后并处理
node官方api
node的核心模块 http模块即可发送请求,摘自node官网api:
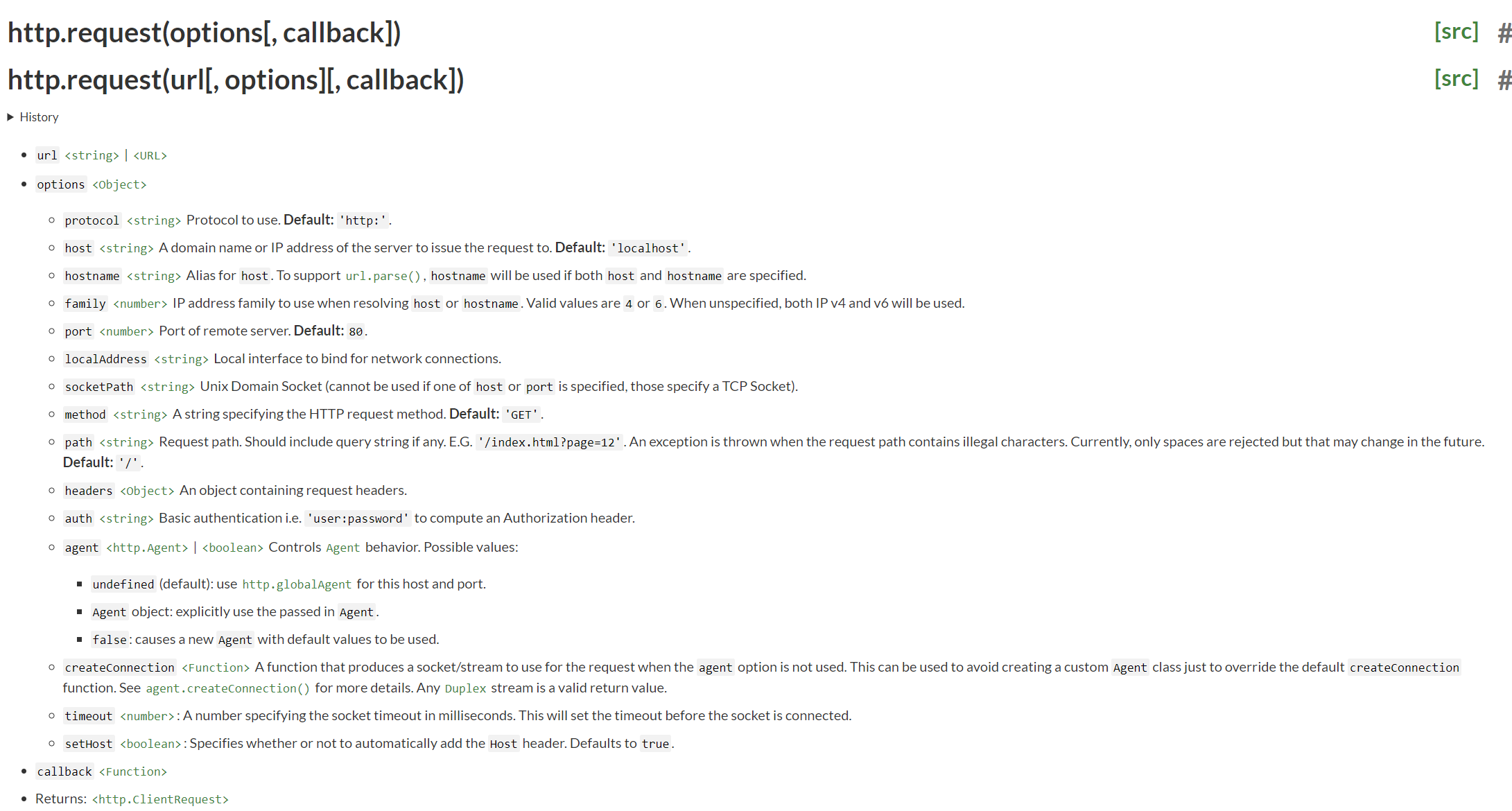
由此可见只需要使用http.request()方法即可发送http请求
发送http请求案例
同学们也可以使用axios库来代替
代码如下:
// 引入http模块
const http = require('http')
// 创建请求对象
let req = http.request('http://web.itheima.com/teacher.html', res => {
// 准备chunks
let chunks = []
res.on('data', chunk => {
// 监听到数据就存储
chunks.push(chunk)
})
res.on('end', () => {
// 结束数据监听时讲所有内容拼接
console.log(Buffer.concat(chunks).toString('utf-8'))
})
})
// 发送请求
req.end()
得到的结果就是整个HTML网页内容
将获取的HTML字符串使用cheerio解析
学习目标:
- 使用cheerio加载HTML
- 回顾jQueryAPI
- 加载所有的img标签的src属性
cheerio库简介

这是一个核心api按照jquery来设计,专门在服务器上使用,一个微小、快速和优雅的实现
简而言之,就是可以再服务器上用这个库来解析HTML代码,并且可以直接使用和jQuery一样的api
官方demo如下:
const cheerio = require('cheerio')
const $ = cheerio.load('<h2 class="title">Hello world</h2>')
$('h2.title').text('Hello there!')
$('h2').addClass('welcome')
$.html()
//=> <html><head></head><body><h2 class="title welcome">Hello there!</h2></body></html>
同样也可以通过jQuery的api来获取DOM元素中的属性和内容
使用cheerio库解析HTML
- 分析网页中所有img标签所在结构
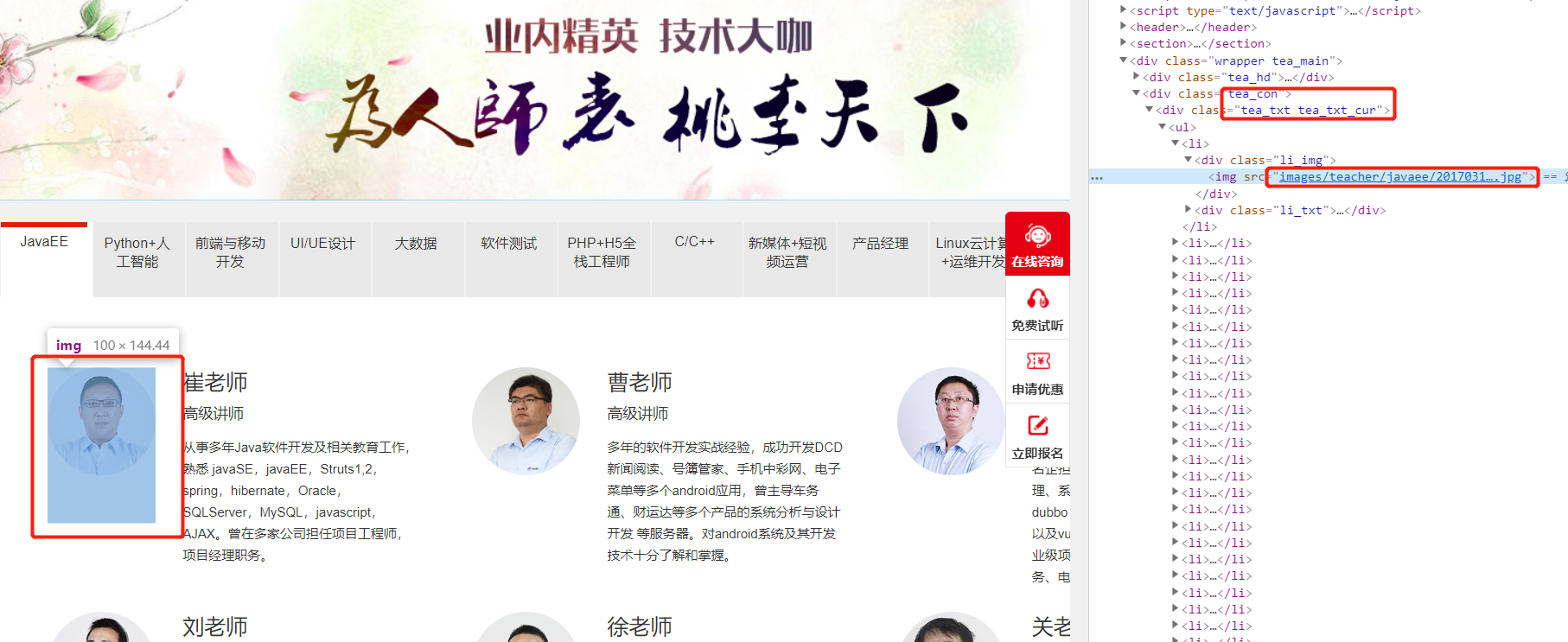
- 使用jQuery API获取所有img的src属性
const http = require('http')
const cheerio = require('cheerio')
let req = http.request('http://web.itheima.com/teacher.html', res => {
let chunks = []
res.on('data', chunk => {
chunks.push(chunk)
})
res.on('end', () => {
// console.log(Buffer.concat(chunks).toString('utf-8'))
let html = Buffer.concat(chunks).toString('utf-8')
let $ = cheerio.load(html)
let imgArr = Array.prototype.map.call($('.tea_main .tea_con .li_img > img'), (item) => 'http://web.itheima.com/' + $(item).attr('src'))
console.log(imgArr)
// let imgArr = []
// $('.tea_main .tea_con .li_img > img').each((i, item) => {
// let imgPath = 'http://web.itheima.com/' + $(item).attr('src')
// imgArr.push(imgPath)
// })
// console.log(imgArr)
})
})
req.end()
使用download库批量下载图片
const http = require('http')
const cheerio = require('cheerio')
const download = require('download')
let req = http.request('http://web.itheima.com/teacher.html', res => {
let chunks = []
res.on('data', chunk => {
chunks.push(chunk)
})
res.on('end', () => {
// console.log(Buffer.concat(chunks).toString('utf-8'))
let html = Buffer.concat(chunks).toString('utf-8')
let $ = cheerio.load(html)
let imgArr = Array.prototype.map.call($('.tea_main .tea_con .li_img > img'), (item) => encodeURI('http://web.itheima.com/' + $(item).attr('src')))
// console.log(imgArr)
Promise.all(imgArr.map(x => download(x, 'dist'))).then(() => {
console.log('files downloaded!');
});
})
})
req.end()
注意事项:如有中文文件名,需要使用base64编码
爬取新闻信息
爬取目标:http://www.itcast.cn/newsvideo/newslist.html

大部分新闻网站,现在都采取前后端分离的方式,也就是前端页面先写好模板,等网页加载完毕后,发送Ajax再获取数据,将其渲染到模板中。所以如果使用相同方式来获取目标网站的HTML页面,请求到的只是模板,并不会有数据:

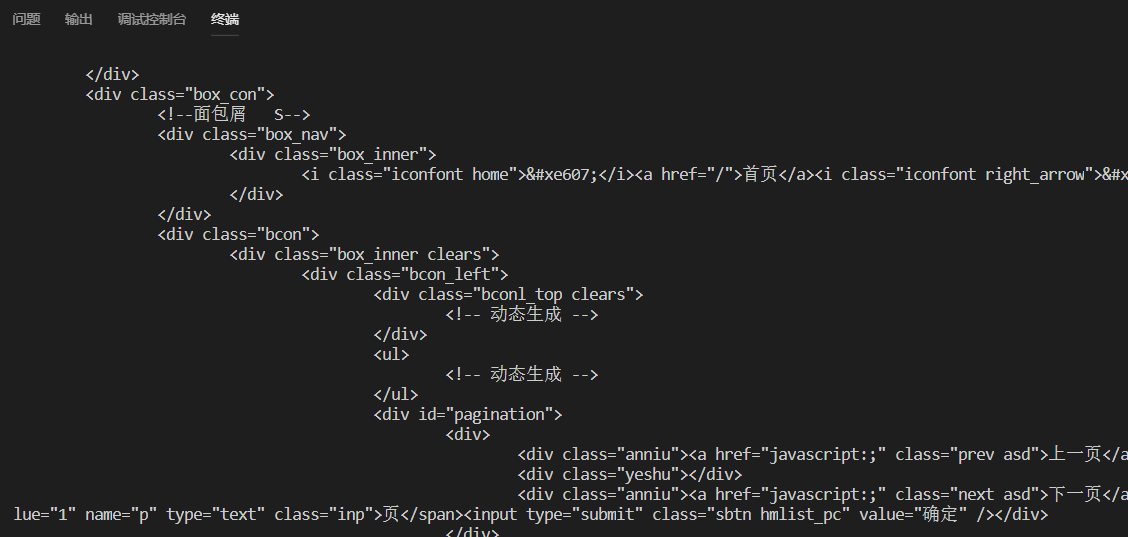
此时,如果还希望使用当前方法爬取数据,就需要分析该网站的ajax请求是如何发送的,可以打开network面板来调试:
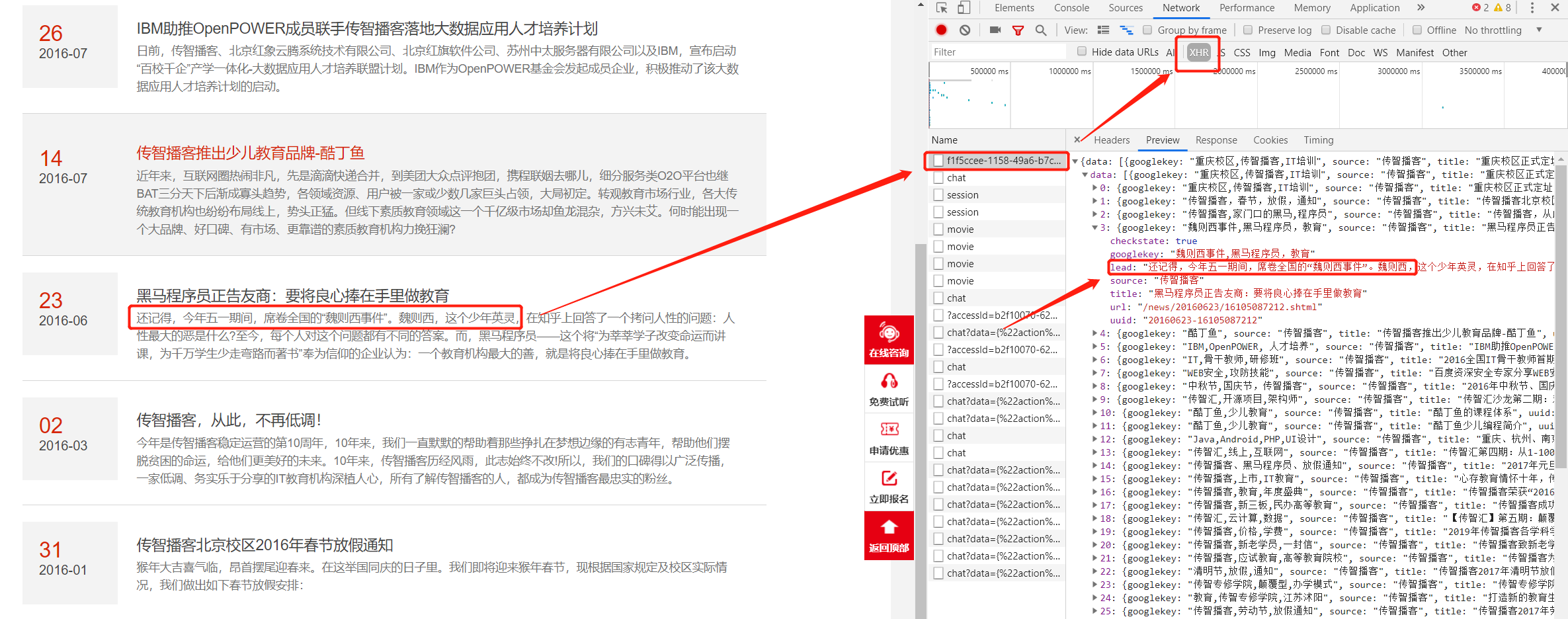
分析得出对应的ajax请求后,找到其URL,向其发送请求即可
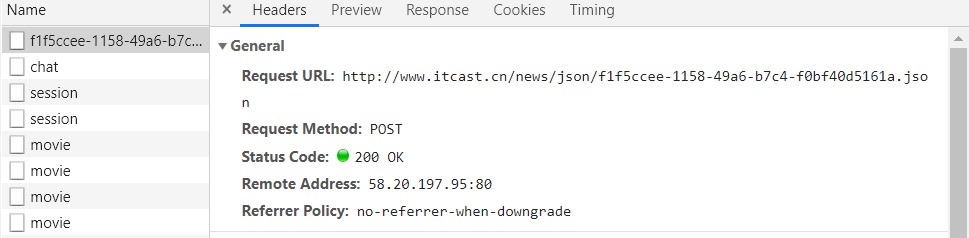
代码如下:
// 引入http模块
const http = require('http')
// 创建请求对象 (此时未发送http请求)
const url = 'http://www.itcast.cn/news/json/f1f5ccee-1158-49a6-b7c4-f0bf40d5161a.json'
let req = http.request(url, res => {
// 异步的响应
// console.log(res)
let chunks = []
// 监听data事件,获取传递过来的数据片段
// 拼接数据片段
res.on('data', c => chunks.push(c))
// 监听end事件,获取数据完毕时触发
res.on('end', () => {
// 拼接所有的chunk,并转换成字符串 ==> html字符串
// console.log(Buffer.concat(chunks).toString('utf-8'))
let result = Buffer.concat(chunks).toString('utf-8')
console.log(JSON.parse(result))
})
})
// 将请求发出去
req.end()
如果遇到请求限制,还可以模拟真实浏览器的请求头:
// 引入http模块
const http = require('http')
const cheerio = require('cheerio')
const download = require('download')
// 创建请求对象 (此时未发送http请求)
const url = 'http://www.itcast.cn/news/json/f1f5ccee-1158-49a6-b7c4-f0bf40d5161a.json'
let req = http.request(url, {
headers: {
"Host": "www.itcast.cn",
"Connection": "keep-alive",
"Content-Length": "0",
"Accept": "*/*",
"Origin": "http://www.itcast.cn",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
"DNT": "1",
"Referer": "http://www.itcast.cn/newsvideo/newslist.html",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Cookie": "UM_distinctid=16b8a0c1ea534c-0c311b256ffee7-e343166-240000-16b8a0c1ea689c; bad_idb2f10070-624e-11e8-917f-9fb8db4dc43c=8e1dcca1-9692-11e9-97fb-e5908bcaecf8; parent_qimo_sid_b2f10070-624e-11e8-917f-9fb8db4dc43c=921b3900-9692-11e9-9a47-855e632e21e7; CNZZDATA1277769855=1043056636-1562825067-null%7C1562825067; cid_litiancheng_itcast.cn=TUd3emFUWjBNV2syWVRCdU5XTTRhREZs; PHPSESSID=j3ppafq1dgh2jfg6roc8eeljg2; CNZZDATA4617777=cnzz_eid%3D926291424-1561388898-http%253A%252F%252Fmail.itcast.cn%252F%26ntime%3D1563262791; Hm_lvt_0cb375a2e834821b74efffa6c71ee607=1561389179,1563266246; qimo_seosource_22bdcd10-6250-11e8-917f-9fb8db4dc43c=%E7%AB%99%E5%86%85; qimo_seokeywords_22bdcd10-6250-11e8-917f-9fb8db4dc43c=; href=http%3A%2F%2Fwww.itcast.cn%2F; bad_id22bdcd10-6250-11e8-917f-9fb8db4dc43c=f2f41b71-a7a4-11e9-93cc-9b702389a8cb; nice_id22bdcd10-6250-11e8-917f-9fb8db4dc43c=f2f41b72-a7a4-11e9-93cc-9b702389a8cb; openChat22bdcd10-6250-11e8-917f-9fb8db4dc43c=true; parent_qimo_sid_22bdcd10-6250-11e8-917f-9fb8db4dc43c=fc61e520-a7a4-11e9-94a8-01dabdc2ed41; qimo_seosource_b2f10070-624e-11e8-917f-9fb8db4dc43c=%E7%AB%99%E5%86%85; qimo_seokeywords_b2f10070-624e-11e8-917f-9fb8db4dc43c=; accessId=b2f10070-624e-11e8-917f-9fb8db4dc43c; pageViewNum=2; nice_idb2f10070-624e-11e8-917f-9fb8db4dc43c=20d2a1d1-a7a8-11e9-bc20-e71d1b8e4bb6; openChatb2f10070-624e-11e8-917f-9fb8db4dc43c=true; Hm_lpvt_0cb375a2e834821b74efffa6c71ee607=1563267937"
}
}, res => {
// 异步的响应
// console.log(res)
let chunks = []
// 监听data事件,获取传递过来的数据片段
// 拼接数据片段
res.on('data', c => chunks.push(c))
// 监听end事件,获取数据完毕时触发
res.on('end', () => {
// 拼接所有的chunk,并转换成字符串 ==> html字符串
// console.log(Buffer.concat(chunks).toString('utf-8'))
let result = Buffer.concat(chunks).toString('utf-8')
console.log(JSON.parse(result))
})
})
// 将请求发出去
req.end()
注意:请求头的内容,可以先通过真正的浏览器访问一次后获取
封装爬虫基础库
以上代码重复的地方非常多,可以考虑以面向对象的思想进行封装,进一步的提高代码复用率,为了方便开发,保证代码规范,建议使用TypeScript进行封装
以下知识点为扩展内容,需要对面向对象和TypeScript有一定了解!
执行tsc --init初始化项目,生成ts配置文件
TS配置:
{
"compilerOptions": {
/* Basic Options */
"target": "es2015",
"module": "commonjs",
"outDir": "./bin",
"rootDir": "./src",
"strict": true,
"esModuleInterop": true
},
"include": [
"src/**/*"
],
"exclude": [
"node_modules",
"**/*.spec.ts"
]
}
Spider抽象类:
// 引入http模块
const http = require('http')
import SpiderOptions from './interfaces/SpiderOptions'
export default abstract class Spider {
options: SpiderOptions;
constructor(options: SpiderOptions = { url: '', method: 'get' }) {
this.options = options
this.start()
}
start(): void {
// 创建请求对象 (此时未发送http请求)
let req = http.request(this.options.url, {
headers: this.options.headers,
method: this.options.method
}, (res: any) => {
// 异步的响应
// console.log(res)
let chunks: any[] = []
// 监听data事件,获取传递过来的数据片段
// 拼接数据片段
res.on('data', (c: any) => chunks.push(c))
// 监听end事件,获取数据完毕时触发
res.on('end', () => {
// 拼接所有的chunk,并转换成字符串 ==> html字符串
let htmlStr = Buffer.concat(chunks).toString('utf-8')
this.onCatchHTML(htmlStr)
})
})
// 将请求发出去
req.end()
}
abstract onCatchHTML(result: string): any
}
export default Spider
SpiderOptions接口:
export default interface SpiderOptions {
url: string,
method?: string,
headers?: object
}
PhotoListSpider类:
import Spider from './Spider'
const cheerio = require('cheerio')
const download = require('download')
export default class PhotoListSpider extends Spider {
onCatchHTML(result: string) {
// console.log(result)
let $ = cheerio.load(result)
let imgs = Array.prototype.map.call($('.tea_main .tea_con .li_img > img'), item => 'http://web.itheima.com/' + encodeURI($(item).attr('src')))
Promise.all(imgs.map(x => download(x, 'dist'))).then(() => {
console.log('files downloaded!');
});
}
}
NewsListSpider类:
import Spider from "./Spider";
export default class NewsListSpider extends Spider {
onCatchHTML(result: string) {
console.log(JSON.parse(result))
}
}
测试类:
import Spider from './Spider'
import PhotoListSpider from './PhotoListSpider'
import NewsListSpider from './NewsListSpider'
let spider1: Spider = new PhotoListSpider({
url: 'http://web.itheima.com/teacher.html'
})
let spider2: Spider = new NewsListSpider({
url: 'http://www.itcast.cn/news/json/f1f5ccee-1158-49a6-b7c4-f0bf40d5161a.json',
method: 'post',
headers: {
"Host": "www.itcast.cn",
"Connection": "keep-alive",
"Content-Length": "0",
"Accept": "*/*",
"Origin": "http://www.itcast.cn",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
"DNT": "1",
"Referer": "http://www.itcast.cn/newsvideo/newslist.html",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Cookie": "UM_distinctid=16b8a0c1ea534c-0c311b256ffee7-e343166-240000-16b8a0c1ea689c; bad_idb2f10070-624e-11e8-917f-9fb8db4dc43c=8e1dcca1-9692-11e9-97fb-e5908bcaecf8; parent_qimo_sid_b2f10070-624e-11e8-917f-9fb8db4dc43c=921b3900-9692-11e9-9a47-855e632e21e7; CNZZDATA1277769855=1043056636-1562825067-null%7C1562825067; cid_litiancheng_itcast.cn=TUd3emFUWjBNV2syWVRCdU5XTTRhREZs; PHPSESSID=j3ppafq1dgh2jfg6roc8eeljg2; CNZZDATA4617777=cnzz_eid%3D926291424-1561388898-http%253A%252F%252Fmail.itcast.cn%252F%26ntime%3D1563262791; Hm_lvt_0cb375a2e834821b74efffa6c71ee607=1561389179,1563266246; qimo_seosource_22bdcd10-6250-11e8-917f-9fb8db4dc43c=%E7%AB%99%E5%86%85; qimo_seokeywords_22bdcd10-6250-11e8-917f-9fb8db4dc43c=; href=http%3A%2F%2Fwww.itcast.cn%2F; bad_id22bdcd10-6250-11e8-917f-9fb8db4dc43c=f2f41b71-a7a4-11e9-93cc-9b702389a8cb; nice_id22bdcd10-6250-11e8-917f-9fb8db4dc43c=f2f41b72-a7a4-11e9-93cc-9b702389a8cb; openChat22bdcd10-6250-11e8-917f-9fb8db4dc43c=true; parent_qimo_sid_22bdcd10-6250-11e8-917f-9fb8db4dc43c=fc61e520-a7a4-11e9-94a8-01dabdc2ed41; qimo_seosource_b2f10070-624e-11e8-917f-9fb8db4dc43c=%E7%AB%99%E5%86%85; qimo_seokeywords_b2f10070-624e-11e8-917f-9fb8db4dc43c=; accessId=b2f10070-624e-11e8-917f-9fb8db4dc43c; pageViewNum=2; nice_idb2f10070-624e-11e8-917f-9fb8db4dc43c=20d2a1d1-a7a8-11e9-bc20-e71d1b8e4bb6; openChatb2f10070-624e-11e8-917f-9fb8db4dc43c=true; Hm_lpvt_0cb375a2e834821b74efffa6c71ee607=1563267937"
}
})
封装后,如果需要写新的爬虫,则可以直接继承Spider类后,在测试类中进行测试即可,仅需实现具体的爬虫类onCatchHTML方法,测试时传入url和headers即可。
而且全部爬虫的父类均为Spider,后期管理起来也非常方便!
第3章 爬虫高级
学习目标:
- 使用Selenium库爬取前端渲染的网页
- 反反爬虫技术
Selenium简介
官方原文介绍:
Selenium automates browsers. That’s it! What you do with that power is entirely up to you. Primarily, it
is for automating web applications for testing purposes, but is certainly not limited to just that. Boring
web-based administration tasks can (and should!) be automated as well.Selenium has the support of some of the largest browser vendors who have taken (or are taking) steps to make
Selenium a native part of their browser. It is also the core technology in countless other browser automation
tools, APIs and frameworks.
百度百科介绍:
Selenium [1] 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),[Mozilla Firefox](https://baike.baidu.com/item/Mozilla
Firefox/3504923),Safari,Google
Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成
.Net、Java、Perl等不同语言的测试脚本。
简单总结:
Selenium是一个Web应用的自动化测试框架,可以创建回归测试来检验软件功能和用户需求,通过框架可以编写代码来启动浏览器进行自动化测试,换言之,用于做爬虫就可以使用代码启动浏览器,让真正的浏览器去打开网页,然后去网页中获取想要的信息!从而实现真正意义上无惧反爬虫手段!
Selenium的基本使用
- 根据平台下载需要的webdriver
- 项目中安装selenium-webdriver包
- 根据官方文档写一个小demo
根据平台选择webdriver
| 浏览器 | webdriver |
|---|---|
| Chrome | chromedriver(.exe) |
| Internet Explorer | IEDriverServer.exe |
| Edge | MicrosoftWebDriver.msi |
| Firefox | geckodriver(.exe) |
| Safari | safaridriver |
选择版本和平台:

下载后放入项目根目录
安装selenium-webdriver的包
npm i selenium-webdriver
自动打开百度搜索“黑马程序员“
const { Builder, By, Key, until } = require('selenium-webdriver');
(async function example() {
let driver = await new Builder().forBrowser('chrome').build();
// try {
await driver.get('https://www.baidu.com');
await driver.findElement(By.id('kw')).sendKeys('黑马程序员', Key.ENTER);
console.log(await driver.wait(until.titleIs('黑马程序员_百度搜索'), 1000))
// } finally {
// await driver.quit();
// }
})();
使用Selenium实现爬虫
在使用Selenium实现爬虫之前,需要搞清楚一个问题:
- 为什么要用Selenium来做爬虫?
了解完后,还需要知道,如何实现爬虫?
- 自动打开拉勾网并搜索”前端”
- 获取所有列表项
- 获取其中想要的信息数据
为什么要用Selenium来做爬虫
目前的大流量网站,都会有些对应的反爬虫机制
例如在拉勾网上搜索传智播客:

找到对应的ajax请求地址,使用postman来测试数据:
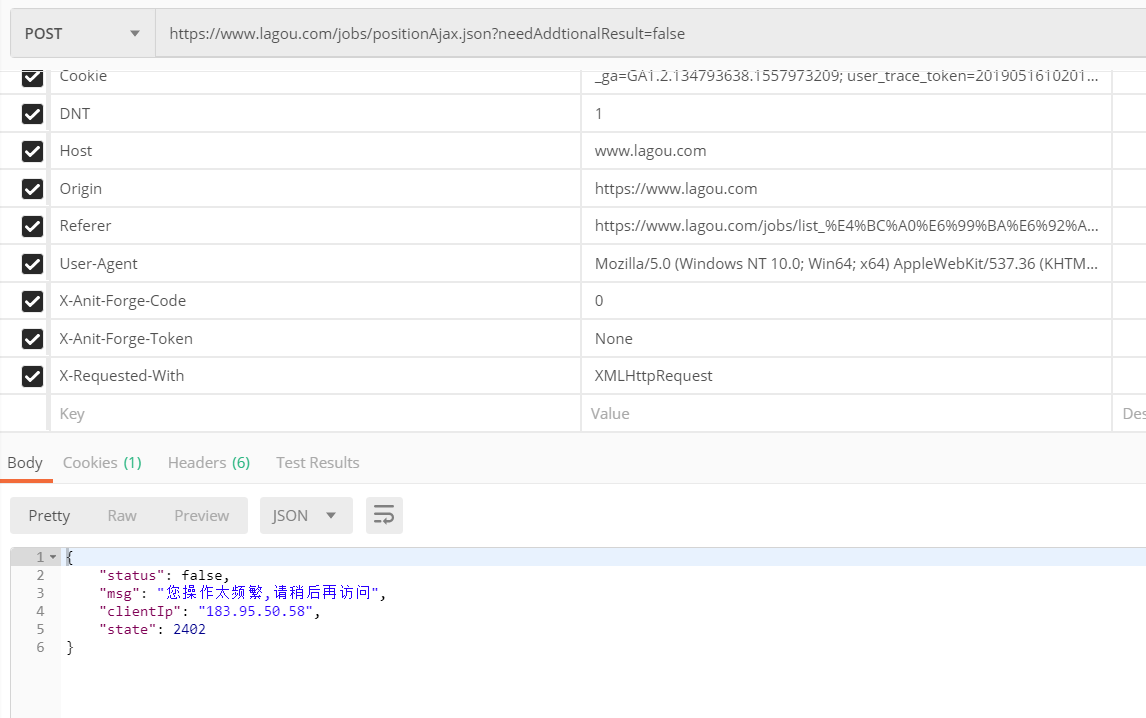
前几次可能会获取到数据,但多几次则会出现操作频繁请稍后再试的问题
而通过Selenium可以操作浏览器,打开某个网址,接下来只需要学习其API,就能获取网页中需要的内容了!
反爬虫技术只是针对爬虫的,例如检查请求头是否像爬虫,检查IP地址的请求频率(如果过高则封杀)等手段
而Selenium打开的就是一个自动化测试的浏览器,和用户正常使用的浏览器并无差别,所以再厉害的反爬虫技术,也无法直接把它干掉,除非这个网站连普通用户都想放弃掉(12306曾经迫于无奈这样做过)
Selenium API学习
核心对象:
- Builder
- WebDriver
- WebElement
辅助对象:
- By
- Key
Builder
用于构建WebDriver对象的构造器
let driver = new webdriver.Builder()
.forBrowser('chrome')
.build();
其他API如下:
可以获取或设置一些Options
如需设置Chrome的Options,需要先导入Options:
const { Options } = require('selenium-webdriver/chrome');
const options = new Options()
options.addArguments('Cookie=user_trace_token=20191130095945-889e634a-a79b-4b61-9ced-996eca44b107; X_HTTP_TOKEN=7470c50044327b9a2af2946eaad67653; _ga=GA1.2.2111156102.1543543186; _gid=GA1.2.1593040181.1543543186; LGUID=20181130095946-9c90e147-f443-11e8-87e4-525400f775ce; sajssdk_2015_cross_new_user=1; JSESSIONID=ABAAABAAAGGABCB5E0E82B87052ECD8CED0421F1D36020D; index_location_city=%E5%85%A8%E5%9B%BD; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1543543186,1543545866; LGSID=20181130104426-da2fc57f-f449-11e8-87ea-525400f775ce; PRE_UTM=; PRE_HOST=www.cnblogs.com; PRE_SITE=https%3A%2F%2Fwww.cnblogs.com%2F; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist_%25E5%2589%258D%25E7%25AB%25AF%25E5%25BC%2580%25E5%258F%2591%3Fkd%3D%25E5%2589%258D%25E7%25AB%25AF%25E5%25BC%2580%25E5%258F%2591%26spc%3D1%26pl%3D%26gj%3D%26xl%3D%26yx%3D%26gx%3D%26st%3D%26labelWords%3Dlabel%26lc%3D%26workAddress%3D%26city%3D%25E5%2585%25A8%25E5%259B%25BD%26requestId%3D%26pn%3D1; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%221676257e1bd8cc-060451fc44d124-9393265-2359296-1676257e1be898%22%2C%22%24device_id%22%3A%221676257e1bd8cc-060451fc44d124-9393265-2359296-1676257e1be898%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D; ab_test_random_num=0; _putrc=30FD5A7177A00E45123F89F2B170EADC; login=true; unick=%E5%A4%A9%E6%88%90; hasDeliver=0; gate_login_token=3e9da07186150513b28b29e8e74f485b86439e1fd26fc4939d32ed2660e8421a; _gat=1; SEARCH_ID=334cf2a080f44f2fb42841f473719162; LGRID=20181130110855-45ea2d22-f44d-11e8-87ee-525400f775ce; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1543547335; TG-TRACK-CODE=search_code')
.addArguments('user-agent="Mozilla/5.0 (iPod; U; CPU iPhone OS 2_1 like Mac OS X; ja-jp) AppleWebKit/525.18.1 (KHTML, like Gecko) Version/3.1.1 Mobile/5F137 Safari/525.20')
WebDriver
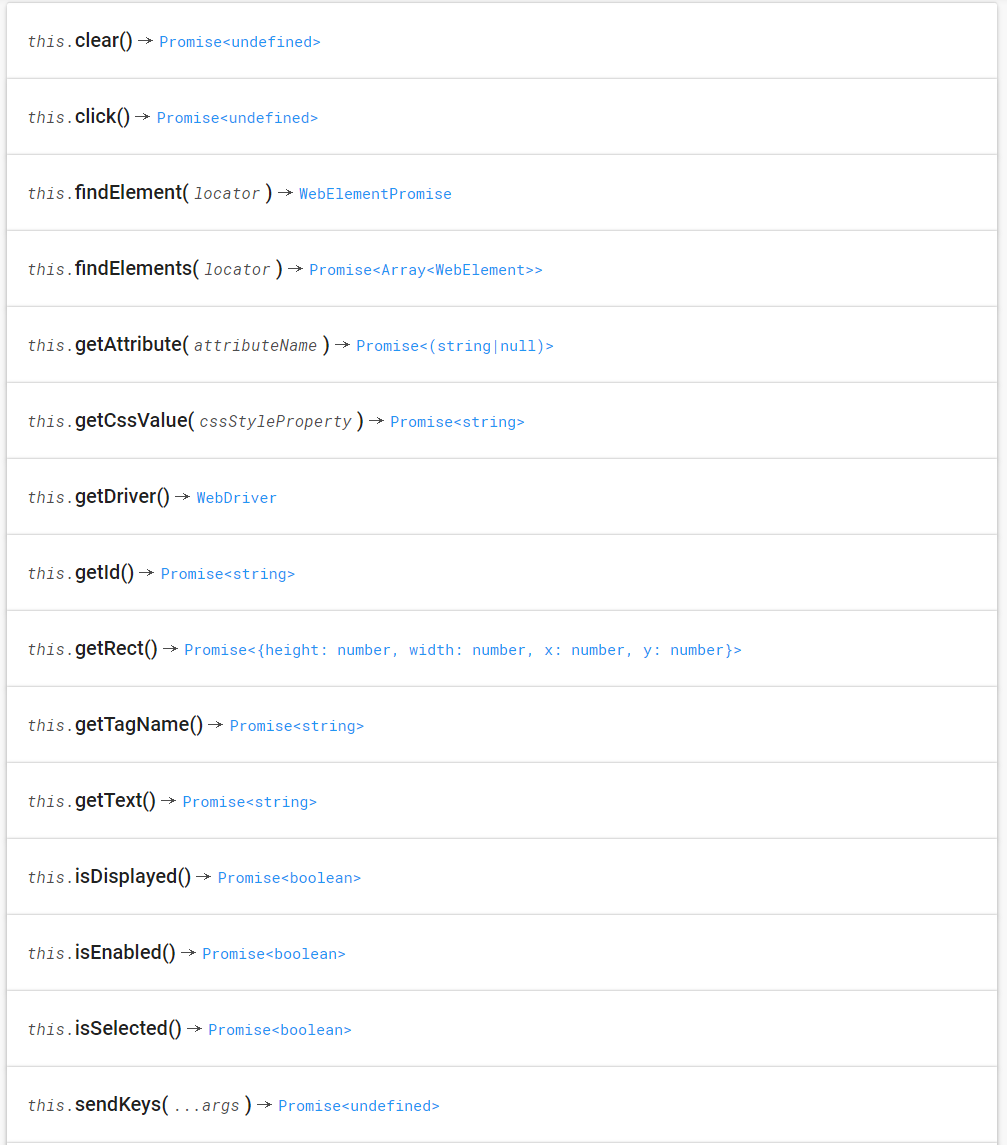
通过构造器创建好WebDriver后就可以使用API查找网页元素和获取信息了:
- findElement() 查找元素
WebElement
- getText() 获取文本内容
- sendKeys() 发送一些按键指令
- click() 点击该元素
自动打开拉勾网搜索”前端”
- 使用driver打开拉勾网主页
- 找到全国站并点击一下
- 输入“前端”并回车
const { Builder, By, Key } = require('selenium-webdriver');
(async function start() {
let driver = await new Builder().forBrowser('chrome').build();
await driver.get('https://www.lagou.com/');
await driver.findElement(By.css('#changeCityBox .checkTips .tab.focus')).click();
await driver.findElement(By.id('search_input')).sendKeys('前端', Key.ENTER);
})();
获取需要的数据
使用driver.findElement()找到所有条目项,根据需求分析页面元素,获取其文本内容即可:
const { Builder, By, Key } = require('selenium-webdriver');
(async function start() {
let driver = await new Builder().forBrowser('chrome').build();
await driver.get('https://www.lagou.com/');
await driver.findElement(By.css('#changeCityBox .checkTips .tab.focus')).click();
await driver.findElement(By.id('search_input')).sendKeys('前端', Key.ENTER);
let items = await driver.findElements(By.className('con_list_item'))
items.forEach(async item => {
// 获取岗位名称
let title = await item.findElement(By.css('.p_top h3')).getText()
// 获取工作地点
let position = await item.findElement(By.css('.p_top em')).getText()
// 获取发布时间
let time = await item.findElement(By.css('.p_top .format-time')).getText()
// 获取公司名称
let companyName = await item.findElement(By.css('.company .company_name')).getText()
// 获取公司所在行业
let industry = await item.findElement(By.css('.company .industry')).getText()
// 获取薪资待遇
let money = await item.findElement(By.css('.p_bot .money')).getText()
// 获取需求背景
let background = await item.findElement(By.css('.p_bot .li_b_l')).getText()
// 处理需求背景
background = background.replace(money, '')
console.log(title, position, time, companyName, industry, money, background)
})
})();
自动翻页
思路如下:
- 定义初始页码
- 获取数据后,获取页面上的总页码,定义最大页码
- 开始获取数据时打印当前正在获取的页码数
- 获取完一页数据后,当前页码自增,然后判断是否达到最大页码
- 查找下一页按钮并调用点击api,进行自动翻页
- 翻页后递归调用获取数据的函数
const { Builder, By, Key } = require('selenium-webdriver');
let currentPageNum = 1;
let maxPageNum = 1;
let driver = new Builder().forBrowser('chrome').build();
(async function start() {
await driver.get('https://www.lagou.com/');
await driver.findElement(By.css('#changeCityBox .checkTips .tab.focus')).click();
await driver.findElement(By.id('search_input')).sendKeys('前端', Key.ENTER);
maxPageNum = await driver.findElement(By.className('totalNum')).getText()
getData()
})();
async function getData() {
console.log(`正在获取第${currentPageNum}页的数据, 共${maxPageNum}页`)
while (true) {
let flag = true
try {
let items = await driver.findElements(By.className('con_list_item'))
let results = []
for (let i = 0; i < items.length; i++) {
let item = items[i]
// 获取岗位名称
let title = await item.findElement(By.css('.p_top h3')).getText()
// 获取工作地点
let position = await item.findElement(By.css('.p_top em')).getText()
// 获取发布时间
let time = await item.findElement(By.css('.p_top .format-time')).getText()
// 获取公司名称
let companyName = await item.findElement(By.css('.company .company_name')).getText()
// 获取公司所在行业
let industry = await item.findElement(By.css('.company .industry')).getText()
// 获取薪资待遇
let money = await item.findElement(By.css('.p_bot .money')).getText()
// 获取需求背景
let background = await item.findElement(By.css('.p_bot .li_b_l')).getText()
// 处理需求背景
background = background.replace(money, '')
// console.log(id, job, area, money, link, need, companyLink, industry, tags, welfare)
results.push({
title,
position,
time,
companyName,
industry,
money,
background
})
}
console.log(results)
currentPageNum++
if (currentPageNum <= maxPageNum) {
await driver.findElement(By.className('pager_next')).click()
await getData(driver)
}
} catch (e) {
// console.log(e.message)
if (e) flag = false
} finally {
if (flag) break
}
}
}
第4章 课程总结
爬虫神通广大,用途非常广泛,主要的目标是为了实现自动化程序,解放程序员的双手
帮助程序员自动获取一些数据,测试一些软件,甚至自动操作浏览器做很多事情
也不乏有些不法分子拿爬虫做一些违法的事情,在此老师希望大家学会爬虫使用在正道上,获取一些我们需要的数据来进行分析
同时,在爬取目标网站之前,建议大家浏览该网站的robots.txt,来确保自己爬取的数据在对方允许范围之内
课程内容涵盖:
- 爬虫简介
- 爬虫的意义
- 各行各业的爬虫
- 使用http模块爬取数据
- http模块发送请求
- 使用cheerio库进行DOM解析
- 一个服务端解析HTML的库,与jQuery API设计相同
- 使用download库进行文件下载
- 使用TypeScript面向对象思想进行爬虫基础库的封装
- 使用Selenium实现爬虫
- 使用Selenium自动翻页
学习不是百米冲刺,而是一场马拉松,现在所学只是起点,更多的是需要大家找到学习方法,不断的学习提升自己,一起加油!
如需本课程完整源码和教学视频,请关注本站微信公众号(xiaomadagege_cn)回复关键词“网络爬虫开发”获取。
相关文章


